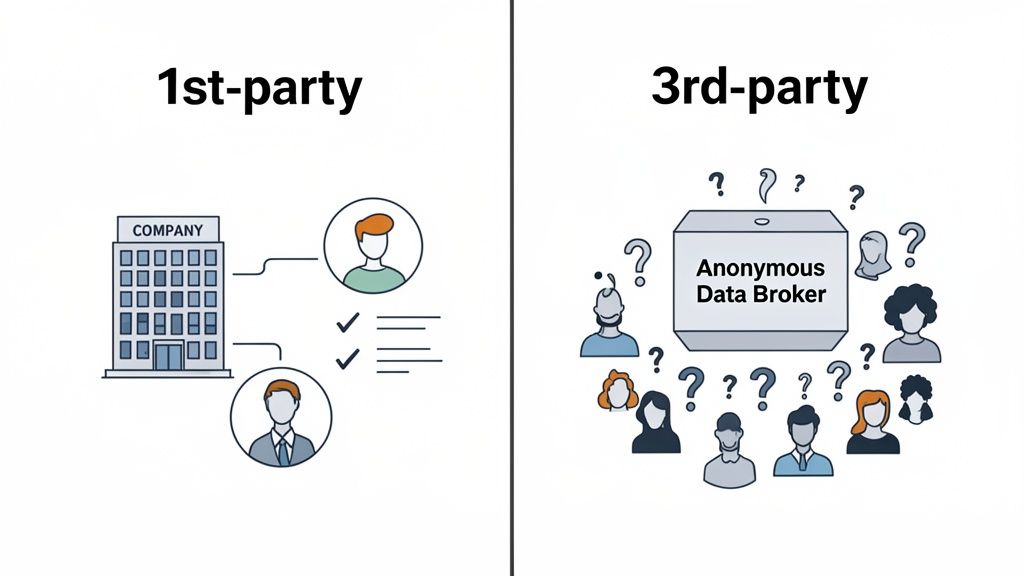
The whole game boils down to one simple question: who collected the data? If you got it straight from your users, that’s first-party data. If it came from some aggregator who has no clue who your users are, that's third-party. This single distinction ripples through everything, from accuracy and privacy all the way down to your product's architecture.
Understanding the Core Difference in Data
When we talk about 1st party vs 3rd party data in software, what we're really talking about is ownership, consent, and control.
Think about it this way: every time a user signs up, clicks a button, or tweaks a setting in your app, they're handing you proprietary, high-quality first-party data. It’s a direct reflection of their intent, and it belongs to you.
Third-party data is the opposite. It’s information that's been scraped, bundled, and sold by data brokers. Sure, it offers massive scale, giving you a wide-angle view of demographics or behaviors for users you've never met. But that scale comes at a steep price: accuracy is questionable, and the collection methods are murky at best.
Why This Distinction Matters Now
Pivoting to first-party data isn't just a "nice-to-have" anymore; it's a strategic must. Privacy laws like GDPR and CCPA have put strict rules on user consent, making direct data collection the only truly safe harbor for compliance. At the same time, users are savvier than ever about their digital footprint and are demanding more say in how their information gets used.
For developers and product teams, building on a foundation of first-party data means you're building on trust. Your personalization efforts are grounded in reality, actual user behavior, not educated guesses from a stranger.
This industry-wide shift, kicked into high gear by browsers phasing out third-party cookies, is forcing a complete rethink of data architecture. The new challenge isn't about hoarding massive, messy datasets. It's about ethically gathering high-quality information to build a better, more reliable user experience.
| Feature | First-Party Data | Third-Party Data |
|---|---|---|
| Source | Collected directly from your own users and platforms. | Aggregated from multiple external sources by a data broker. |
| Accuracy | High; based on direct user interactions and inputs. | Variable to low; often inferred or modeled, not deterministic. |
| Privacy | High; clear consent mechanisms and direct user relationship. | Low; consent is often indirect or bundled, raising compliance risks. |
| Cost | Low acquisition cost, but requires investment in collection tools. | High acquisition cost, often purchased on a subscription basis. |
A Multi-Dimensional Comparison of Data Sources
Deciding between first-party and third-party data isn't just a technical choice, it's a strategic move that directly impacts your product's performance, user trust, and long-term health. When you dig into the 1st party vs 3rd party debate, you find critical trade-offs across a few key areas. Moving beyond a simple pro-con list helps product teams and developers make choices that actually line up with their goals.
The first place to look is the most fundamental: the quality and reliability of the information itself.

Accuracy and Reliability
First-party data is deterministic. You collect it yourself, creating a direct record of user actions like clicks, purchases, and form submissions. This makes it the undisputed gold standard for accuracy, a solid foundation for personalizing core features in your app.
Third-party data, on the other hand, is probabilistic. It’s usually aggregated from multiple sources and modeled to guess user attributes like demographics or interests. While it can be useful for broad market analysis, its built-in imprecision makes it a gamble for powering user-facing features where getting it right matters.
Privacy and Consent
The ground has completely shifted under our feet when it comes to data privacy, putting consent right at the center of any data strategy. With first-party data, you own the consent process. You can be transparent with users and ensure you’re compliant with regulations like GDPR, building trust one interaction at a time.
Third-party data brings a whole host of privacy risks with it. The chain of consent is often murky at best, and you have almost no control over how the data was originally collected. Leaning on these sources can expose your company to serious legal and reputational blowback if that data turns out to be non-compliant.
The core trade-off is clear: third-party sources offer scale at the cost of control and certainty. For mission-critical functions, the verified, consent-driven nature of first-party data is non-negotiable.
This brings us to the practical reality of actually getting these different data types into your tech stack.
Integration Complexity and Cost
Integrating first-party data means an upfront investment in your own infrastructure, analytics tools, databases, and event tracking. But once you've built it, that data flows smoothly through your ecosystem, becoming a cost-effective and fully controlled asset.
Third-party data typically comes in via APIs, creating external dependencies that can become points of failure. The modern API economy puts this challenge in sharp relief; while 71% of businesses use third-party APIs, 60% admit they spend way too much time troubleshooting them. This is a hidden cost. You end up paying twice: once for the API subscription, and again in developer hours spent on maintenance. You can dive deeper into the trends of API consumption to get the full picture.
The table below breaks these dimensions down for a clear, head-to-head view.
First-Party vs Third-Party Data: A Head-to-Head Comparison
This table breaks down the key differences between first-party and third-party sources across critical operational and strategic dimensions.
| Dimension | First-Party Data and APIs | Third-Party Data and APIs |
|---|---|---|
| Accuracy | Deterministic: Based on direct, verifiable user actions. High reliability for core product functions. | Probabilistic: Often inferred or modeled. Risk of inaccuracy and outdated information. |
| Privacy & Consent | High Control: You manage the entire consent lifecycle directly with the user, ensuring compliance. | Low Control: Consent is indirect and often opaque, creating significant compliance risks. |
| Integration | Internal Dependency: Requires upfront build-out but offers long-term stability and control. | External Dependency: Faster to implement initially but introduces vendor lock-in and maintenance overhead. |
| Cost | Operational Cost: Investment in infrastructure and engineering to collect and manage data. | Subscription Cost: Direct fees for data access, plus hidden costs of integration and maintenance. |
Ultimately, the right choice always comes down to the specific use case. If you're personalizing a user's dashboard with their own activity, first-party data is the only sane option. But if you need to enrich a user profile with publicly available company information, a specialized third-party API can be a powerful and efficient way to get the job done.
Why the Shift to First-Party Data Is Accelerating
The move away from third-party data isn't some gradual trend; it's a fundamental market correction. For years, the digital advertising world was propped up by third-party cookies that tracked users across the web. That foundation is now crumbling, and fast.
Major web browsers are systematically pulling the plug on these cookies, dismantling the very infrastructure that powered cross-site tracking. This "cookiepocalypse" is a direct threat to any business model that leans on aggregated, third-party audience data for targeting. It’s forcing a pivot to more direct, sustainable ways of understanding customers.
The Growing Demand for Privacy and Control
Beyond the tech, consumer attitudes have completely changed. People are more aware, and more protective, of their digital footprint. This shift has been solidified by robust privacy laws like GDPR in Europe and CCPA in California, which have set a new global standard for data handling built on transparency and explicit consent.
This consumer-led push for privacy means that passively collected, opaque third-party data isn't just inaccurate anymore; it's a liability. Businesses now have a powerful incentive to build direct relationships with their customers, creating a clear value exchange where people willingly share information. The 1st party vs 3rd party debate has officially moved from a technical problem to a core business strategy.
The new competitive advantage isn’t about how much data you can buy, but the quality of the data you can ethically and directly collect. This is about building trust, not just databases.
AI and the Premium on High-Quality Data
The explosion of AI and large language models (LLMs) has only thrown more fuel on the fire. To train effective personalization models, AI systems need massive amounts of high-quality, granular data. First-party data has quickly become the gold standard for this.
Unlike third-party sources riddled with gaps and inconsistencies, direct data offers the precision that modern AI demands. This transition is being supercharged by Google’s deprecation of third-party cookies in Chrome, a browser with over 50% of global usage, which is expected to wipe out as much as 80% of third-party cookie prevalence. You can learn more about how first-party data is shaping AI strategies.
As companies pour more resources into AI-driven experiences, the need for clean, reliable, and ethically sourced first-party data becomes non-negotiable. It's the only way to create accurate, unbiased, and genuinely helpful personalization. Companies that master this will build better products, period. Those who don't will be left behind. And even with this direct data, you'll still want to find ways to identify anonymous website visitors and turn them into known, engaged users.
Your first-party data is the bedrock of your product strategy, but on its own, it tells an incomplete story. It shows you what a user does inside your app but reveals very little about who they are professionally. This is where a hybrid approach, blending your own data with specialized third-party APIs, can create a far richer, more personalized experience without the privacy headaches of old-school data brokers.
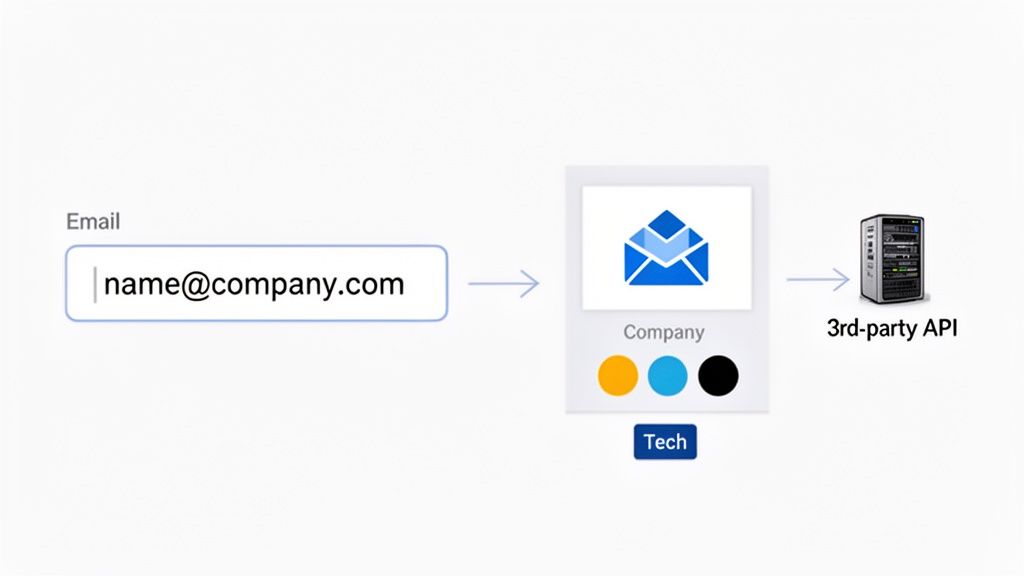
The trick is to use a simple first-party signal, like a user's company email, to pull in public, non-sensitive brand information. This model respects user privacy while unlocking a goldmine of contextual data. It's a smart, modern compromise in the 1st party vs 3rd party debate.
This isn't just a niche tactic anymore; it's becoming a core business practice as API-first development takes over. Recent studies show that a staggering 82% of organizations now prioritize an API-first approach. For the 25% that are fully API-first, these integrations are serious business, with 43% generating over a quarter of their revenue directly from APIs.
From Domain to Brand Identity in an Instant
This is exactly where services like Brand.dev fit in, acting as a brand data enrichment layer. When a new user signs up with their work email, you can make a single, simple API call to retrieve their company’s complete brand kit.
That call can instantly deliver assets like:
- Official Logos: Perfect for personalizing dashboards and welcome emails.
- Brand Colors: To automatically theme the user interface.
- Company Descriptions: For adding real context to CRM profiles.
- Industry Data: To segment users and tailor onboarding from day one.
This workflow transforms a simple email address, a piece of first-party data you already have, into a rich, professional profile that makes your product feel instantly familiar. If you're looking for more ways to gather public insights, a good online brand monitoring guide can also offer some really practical workflows.
The goal isn’t to replace first-party data but to augment it intelligently. By using verified, public brand information, you add a layer of personalization that would be impossible to gather during signup without creating a ton of friction.
Practical Use Cases for Hybrid Enrichment
This approach quickly moves from theory into tangible product improvements. For example, a SaaS platform can use a company data API to automate one of the most critical parts of the customer journey: onboarding. Instead of dropping a user into a generic, gray dashboard, you can immediately apply their company's branding. Your product instantly feels like an integrated part of their toolkit from the very first login.
Sales and marketing teams see huge benefits, too. Imagine your CRM records automatically populating with company logos and up-to-date descriptions. It gives sales reps valuable context before a call and makes every interaction more relevant. This strategic use of third-party APIs bridges the gap between what you know from user behavior and who your users are in the business world, creating a much more complete and actionable picture.
The theory behind 1st-party vs. 3rd-party data is interesting, but the real magic happens when you stop picking sides and start blending them. A hybrid strategy uses a first-party data point, something a user gives you directly, as a key to unlock a world of third-party enrichment. It's the best way to deliver deep personalization without wading into the privacy minefield of traditional data brokers.
For any SaaS team, this approach is a game-changer. It’s how you create powerful, context-aware experiences from the second a user signs up, making your product feel instantly familiar and woven into their professional world. Let's walk through three practical ways to put this into action.
Automated Onboarding Personalization
A user’s email address is the perfect first-party key. When they sign up, you can use their domain to fetch public brand assets and instantly customize their entire experience.
- Collect the email: The user signs up with their work email, like
jane@acme.com. - Make an API Call: Your backend fires off a server-side call to a brand API like Brand.dev, passing along the domain
acme.com. - Receive Brand Data: The API returns a neat JSON object packed with the company's logo, brand colors, name, and description.
- Personalize the UI: Your application takes these assets and dynamically injects them into the user's new dashboard, theming the interface and dropping in their company logo.
It’s a small technical step with a massive impact. You’ve just transformed a generic onboarding flow into a bespoke welcome, showing the user you get their context from the very first click.
This pattern turns a standard signup form into an intelligent personalization engine. It's a low-friction way to demonstrate immediate value and boost user engagement from day one.
Intelligent Transaction Enrichment
For fintech and billing platforms, raw transaction lists are just plain confusing. A hybrid data strategy can clean them up, making them clear and professional.
Imagine a user staring at a charge from "STRIPE-ABC Inc." on their statement. It’s cryptic and a little alarming. A brand enrichment API can translate this into a recognizable identity. The process is simple: send the company name from the transaction record to the API, and it returns the official name ("ABC Incorporated") and logo.
This single step adds a layer of trust and clarity that dramatically cuts down on customer support tickets. This type of B2B data enrichment is non-negotiable for building professional-grade financial tools. To see more on this, check out our guide on the power of B2B data enrichment.
AI-Powered Content Generation
Large Language Models (LLMs) are incredibly powerful, but they operate in a vacuum, they have no idea what a specific brand looks or sounds like. A hybrid data strategy fixes this by feeding structured, third-party brand data directly into your AI prompts.
- Workflow: When a user asks for a new marketing email, your system first pulls their company's brand kit, colors, fonts, voice guidelines, from a brand API.
- Prompt Engineering: This structured data is then injected right into the LLM prompt, telling the AI to generate copy and visuals that stick to those guidelines like glue.
This ensures that any AI-generated content is consistently on-brand, saving users hours of manual tweaking. We're seeing this pattern everywhere now. For example, solutions like the AI-powered support application supportgpt showcase how feeding contextual data into AI makes the output infinitely more useful.
These patterns prove that the best approach isn’t about choosing between first-party and third-party data. It's about a smart synthesis of both.
Choosing the Right Data Strategy for Your Product
The whole 1st party vs 3rd party data debate isn't really about picking a winner. It’s about building a smart, adaptable system that knows when to use which. The right approach for your product always comes down to context, a balancing act between security, user experience, and strategic growth.
But let's get one thing straight: for core product functions, the answer is always first-party data.
When you're dealing with user authentication, personal information, or any sensitive in-app activity, a pure first-party approach is non-negotiable. This data is your direct line to the user, built on a foundation of trust and explicit consent. Relying on anything else introduces unacceptable risks to privacy and data integrity.
Finding the Hybrid Sweet Spot
That said, a strict first-party-only strategy can leave valuable context on the table. This is where a hybrid model, powered by vetted, developer-first APIs, becomes the most efficient and scalable path forward. The idea is simple: you use a known first-party data point as a key to unlock a world of public, non-sensitive third-party information.
This process flow shows how a hybrid strategy can turn a single piece of user data into a rich, personalized experience.
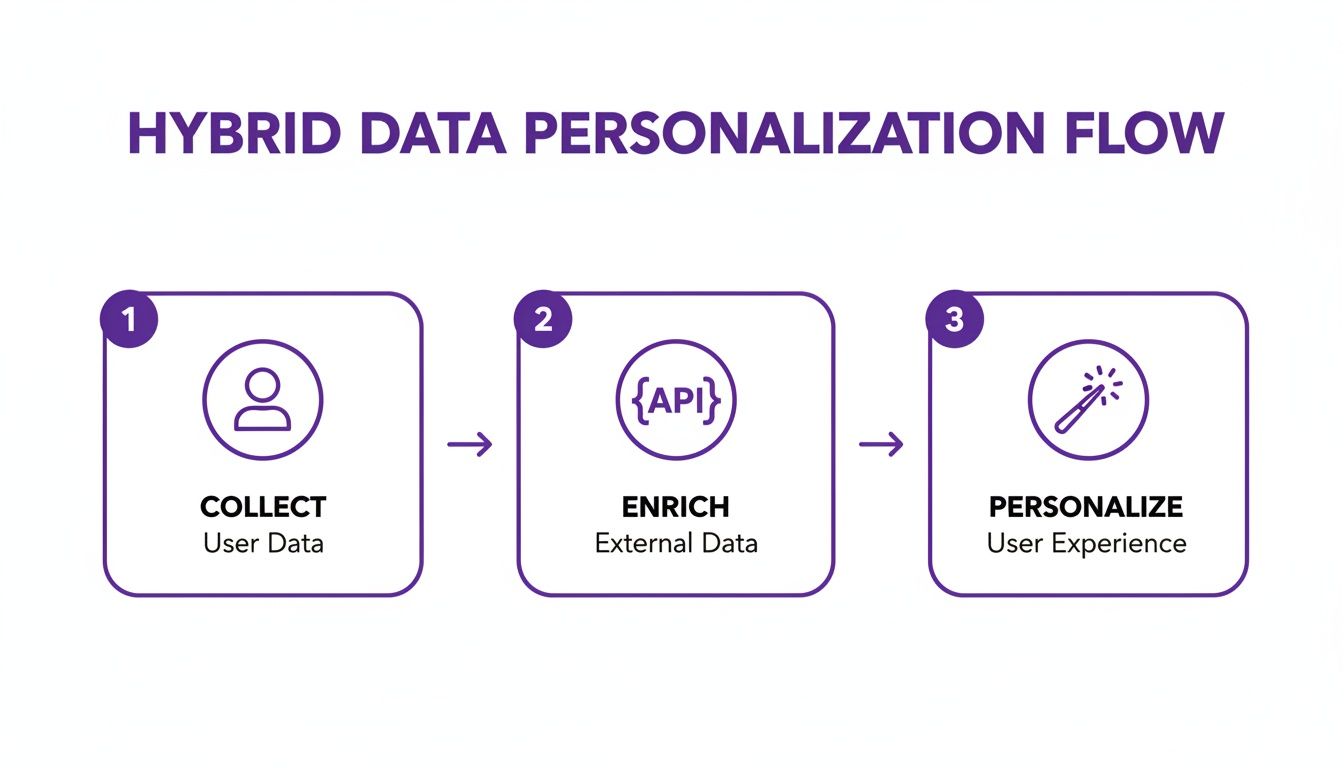
The workflow is powerful in its simplicity: collect a first-party signal, enrich it via an API, and deliver a personalized user experience.
This balanced strategy allows you to maintain a secure core while intelligently augmenting profiles with valuable brand data. It solves the cold start problem for new users and adds a layer of professional polish to your product without ever compromising on privacy.
The most effective data strategies are not built on absolutes. They are built on a clear understanding of when to protect core user data with a first-party wall and when to enrich it with trusted, specialized third-party sources.
Your Decision Framework
Your path forward becomes clear when you frame the decision around specific product goals. Use this simple framework to guide your implementation:
- For Security and Core Data: If it involves passwords, personal details, or user-generated content, stick to 100% first-party data. No exceptions.
- For Onboarding and Personalization: If you want to customize a new user's dashboard with their company branding, a hybrid model is the perfect fit.
- For AI and Content Generation: To ensure AI-produced assets are consistently on-brand, use a hybrid approach to feed structured brand data directly into your prompts.
By adopting this nuanced view, you can build a data strategy that is secure, compliant, and delivers the kind of personalized experiences that truly drive engagement and retention.
Ready to implement a powerful hybrid data strategy? With Brand.dev, you can instantly enrich user profiles with logos, colors, and complete brand kits using a single API call. Start building for free.